Robots.txt cos’è?
Il robots.txt è uno strumento fondamentale nel mondo dell‘ottimizzazione per i motori di ricerca. Questo file di testo è creato dai webmaster per istruire i bot del web, in particolare i robot dei motori di ricerca, su come esplorare le pagine del sito.
Il file robots.txt fa parte del robots exclusion protocol (REP), un insieme di standard web che regolano come i robot esplorano il web, accedono e indicizzano i contenuti e li servono agli utenti. Il REP comprende anche direttive come i meta robots, nonché istruzioni a livello di pagina, sotto-directory o sito su come i motori di ricerca devono trattare i link, ad esempio “follow” o “nofollow”.
In pratica, i file robots.txt indicano se determinati user-agent (software di crawling web) possono o non possono esplorare parti di un sito web. Queste istruzioni di crawling vengono specificate “disabilitando”(disallow) o “abilitando”(allow) il comportamento di determinati (o tutti) user-agent.
Formato del file robots.txt
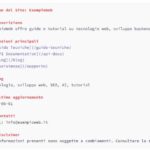
In linea generale, il file robots.txt è fatto in questo modo:
User-agent: [User-agent]
Disallow: [stringa URL da non esplorare]
Insieme, queste due righe costituiscono un file robots.txt completo, anche se un singolo file può contenere più righe di user-agent e direttive (disallow, allow, crawl-delays, ecc.).
All’interno di un file robots.txt, ogni insieme di direttive va separato da un’interruzione di riga.
File robots.txt esempi
Ecco alcuni esempi di robots.txt in azione per un sito www.example.com:
Impedire l’accesso al sito a tutti i bot
User-agent: *
Disallow: /
Utilizzando questa sintassi nel file robots.txt, impediamo a tutti i web crawler di non esplorare nessuna pagina su www.example.com, compresa la homepage.
Consentire l’accesso al sito a tutti i crawler
User-agent: *
Disallow:
Utilizzando questa sintassi, comunichiamo ai web crawler di esplorare tutte le pagine di www.example.com, compresa la homepage.
Impedire al bot di Google di accedere a delle sottocartelle del sito
User-agent: Googlebot
Disallow: /esempio-sottocartella/
Con questa sintassi, comunichiamo al bot di Google di non accedere a quelle pagine che contengono la stringa /esempio-sottocartella/ nell’URL, come per esempio www.example.com/esempio-sottocartella/
Bloccare l’accesso a una pagina web specifica
User-agent: Bingbot
Disallow: /esempio-sottocartella/pagina-bloccata.htmlBloccare URL con query string
User-agent: *
Disallow: /*add-to-cart=
Nell’esempio sopra, stiamo dicendo a tutti i bot (rappresentati da “*”) di non indicizzare alcuna pagina che contiene “?add-to-cart=” nella sua query string. Ciò impedirà l’indicizzazione delle pagine del carrello che utilizzano questa query string specifica.
Come funziona il file robots.txt?
Prima di comprendere il funzionamento del file robots.txt, è fondamentale conoscere i due principali compiti svolti dai bot dei motori di ricerca:
- Esplorazione del web per scoprire i contenuti.
- Indicizzazione di tali contenuti in modo che possano essere serviti agli utenti in cerca di informazioni.
Per esplorare i siti web, i motori di ricerca seguono i link per passare da un sito all’altro, esplorando molti miliardi di link e siti web. Questo comportamento di esplorazione è talvolta noto come “crawling”.
Prima di accedere a un sito web, il crawler cerca il file robots.txt. Se lo trova, leggerà prima quel file e poi passerà a scansionare il sito. Il file robots.txt contiene direttive su cosa il crawler può o non può esplorare. Se il file robots.txt non contiene direttive che vietano l’esplorazione di pagine o sezioni del sito, il crawler scansionerà la pagina e seguirà i link per esplorarla completamente.
Cosa sapere del robots.txt
- Dove mettere il file robots.txt: Per essere trovato, un file robots.txt deve essere collocato nella directory di livello superiore del sito web.
- Il nome del file robots.txt è case sensitive: Il file robots.txt è sensibile alle maiuscole e minuscole e deve essere denominato “robots.txt”, senza considerare altre varianti.
- Alcuni bot possono ignorarlo: Alcuni user-agent possono scegliere di ignorare il file robots.txt. Questo è particolarmente comune con crawler di scraping malevolo, come i robot malware o quelli che raccolgono indirizzi email.
- Il file robots.txt è sempre accessibile a tutti: Il file robots.txt è accessibile a tutti. Non ci credi? Vai su un sito a caso e aggiungi /robots.txt alla fine del root domain!
- File robots.txt separati per domini e sottodomini: Ciascun sotto dominio su un dominio radice utilizza file robots.txt separati. Ciò significa che sia blog.example.com che example.com dovrebbero avere i propri file robots.txt (ad es. blog.example.com/robots.txt e example.com/robots.txt).
- Indicazione delle posizioni dei sitemap: È una pratica consigliata indicare la posizione di eventuali sitemap associate al dominio nella parte finale del file robots.txt.
Sintassi ed elementi principali del robots.txt
La sintassi del file robots.txt può essere considerata come il “linguaggio” dei file robots.txt. Ci sono cinque termini comuni che probabilmente incontrerai in un file robots:
- User-agent: Il crawler web specifico a cui stai dando istruzioni di esplorazione (di solito un motore di ricerca). Puoi trovare una lista di agenti utente comuni qui.
- Disallow: Il comando utilizzato per dire a uno user-agent di non esplorare una particolare URL. È consentita solo una riga “Disallow:” per ciascuna URL.
- Allow (applicabile solo a Googlebot): Il comando per dire a Googlebot di poter accedere a una pagina o a una sottocartella anche se la sua pagina madre o sottocartella potrebbe essere vietata.
- Crawl-delay: Quanti secondi un crawler dovrebbe attendere prima di caricare e esplorare il contenuto della pagina. Nota che Googlebot non riconosce questo comando, ma il tasso di crawl può essere impostato tramite Google Search Console.
- Sitemap: Usato per indicare la posizione di eventuali sitemap XML associati a questa URL. Nota che questo comando è supportato solo da Google, Ask, Bing e Yahoo.
Caratteri speciali del file robots.txt
Per quanto riguarda le URL da bloccare o consentire, i file robots.txt possono diventare piuttosto complessi in quanto consentono l’uso di corrispondenza dei modelli per coprire una gamma di opzioni di URL possibili. Per questa ragione, Google e Bing accettano entrambi due espressioni regolari che possono essere utilizzate per identificare le pagine o le sottocartelle che un SEO desidera escludere. Questi due caratteri sono l’asterisco (*) e il segno di dollaro ($).
- * è un carattere jolly che rappresenta qualsiasi sequenza di caratteri.
- $ corrisponde alla fine dell’URL.
Google offre una ricca documentazione su come deve essere formato il file robots e di come viene interpretato dai sui bot.
Dove si trova il robots.txt su un sito?
Ogni volta che un motore di ricerca e altri robot di web crawling (come il crawler di Facebook) visitano un sito web, cercano il file robots.txt nella directory principale. Se il bot non trova il file robots.txt all’indirizzo www.example.com/robots.txt, presumirà che il sito non ne abbia uno e procederà ad esplorare l’intero contenuto della pagina (e potenzialmente anche dell’intero sito). Anche se il file robots.txt esistesse, ad esempio in example.com/index/robots.txt o www.example.com/homepage/robots.txt, non verrebbe scoperto dagli agenti utente e quindi il sito verrebbe trattato come se non avesse un file robots.
Per garantire che il proprio file robots.txt sia individuato, è sempre consigliabile posizionarlo nella directory principale o nel dominio radice del sito web.
Perché il file robotst.txt è importante
Il file robots.txt è essenziale per controllare l’accesso dei crawler a specifiche aree del tuo sito web. Sebbene possa essere rischioso vietare accidentalmente a Googlebot di esplorare l’intero sito (!!), ci sono situazioni in cui un file robots.txt può rivelarsi estremamente utile.
- Prevenire la visualizzazione di contenuti duplicati nei risultati dei motori di ricerca (nota che spesso è preferibile utilizzare meta robots per questo scopo).
- Mantenere completamente private alcune sezioni del tuo sito web (come il sito di sviluppo del tuo team di ingegneria).
- Evitare che le pagine dei risultati di ricerca interna siano mostrate nei risultati di ricerca pubblici (SERP).
- Specificare la posizione delle mappe del sito.
- Impedire ai motori di ricerca di indicizzare determinati file presenti sul tuo sito web, come immagini, PDF, e altro.
- Stabilire un ritardo nell’esplorazione per evitare il sovraccarico dei server quando i crawler caricano più contenuti contemporaneamente.
Come creare un file robots.txt
Se hai scoperto di non avere un file robots.txt o desideri modificarlo, la creazione di uno è un processo semplice. Questo articolo di Google guida attraverso il processo di creazione del file robots.txt e questo strumento ti consente di verificare se il tuo file è configurato correttamente.
Se vuoi provare a crearne uno, puoi utilizzare un generatore come questo.
File robots.txt e SEO: alcuni consigli
È fondamentale assicurarsi di non bloccare alcun contenuto o sezioni del tuo sito web che desideri far esplorare.
I link presenti nelle pagine bloccate dal robots.txt non saranno seguiti. Ciò significa che:
- A meno che non siano collegati anche da altre pagine accessibili dai motori di ricerca (cioè pagine non bloccate tramite robots.txt, meta robots o altro), le risorse collegate non verranno esplorate e potrebbero non essere indicizzate.
- Nessun link equity potrà essere trasmesso dalla pagina bloccata alla destinazione del link. Se hai pagine alle quali desideri far passare il link equity, è consigliabile utilizzare un meccanismo diverso dal robots.txt.
Va notato che alcuni motori di ricerca utilizzano diversi agenti utente. Ad esempio, Google utilizza Googlebot per la ricerca organica e Googlebot-Image per la ricerca di immagini. La maggior parte degli agenti utente dello stesso motore di ricerca segue le stesse regole, quindi di solito non è necessario specificare direttive per ciascuno dei crawler multipli di un motore di ricerca. Tuttavia, la possibilità di farlo consente di regolare in dettaglio come il contenuto del tuo sito viene esplorato.
Controlli SEO sul file robots.txt
In fase di SEO audit, il check del file robots.txt è un passo imprescindibile. Come agenzia SEO, ci è capitato spesso di analizzare un sito web e riscontrare errori critici sui file robots.txt. Spesso venivano bloccate pagine utili per il posizionamento SEO o risorse fondamentali per il corretto rendering della pagina.
Quindi, ora che hai compreso meglio come funziona il file robots.txt, controlla sempre che:
- non ci siano risorse JS, CSS, immagini e documenti bloccati
- non ci siano pagine importanti per la visibilità organica bloccate con Disallow
- non ci siano tentativi di deincidizzare pagine con direttiva Disallow
- che sia indicata la locazione della sitemap
Qual è la differenza tra robots.txt e meta robots e x-robots?
In breve, robots.txt controlla l’accesso a livello di sito, meta robots gestisce il comportamento delle pagine, e X-Robots-Tag offre una maggiore flessibilità a livello di pagina e risorse. Vediamo nel dettaglio quali sono le differenze:
- Robots.txt:
- File di testo situato sul server web.
- Controlla l’accesso dei robot a livello di sito o directory.
- Fornisce direttive “disallow” o “allow” per specifiche pagine o directory.
- Funziona a livello di sito.
- Meta Robots:
- Tag HTML inserite nelle pagine web.
- Controlla il comportamento dei bot a livello di singola pagina.
- Fornisce direttive come “noindex,” “nofollow,” ecc.
- Influenza direttamente l’indicizzazione e il comportamento delle pagine.
- X-Robots-Tag (X-Robots):
- Intestazioni HTTP per comunicare direttive ai robot.
- Controlla il comportamento delle pagine individuali e risorse come immagini.
- Fornisce direttive come “noindex,” “nofollow,” ecc.
- È flessibile e può essere applicato a risorse diverse dalle pagine.